
구글의 'HBM 독립 선언'?
TPU V8이 설계 판도를 뒤흔드는 5가지 핵심 전략

1. 도입부: HBM 만능 시대에 던져진 파격적인 질문
현재 AI 가속기 시장은 고 대역폭 메모리(HBM) 확보를 위한 총성 없는 전쟁터입니다.
엔비디아(NVIDIA)가 주도하는 HBM 중심의 아키텍처는 성능 면에서는 독보적이지만,
공급 부족과 천정부지로 치솟는 가격, 그리고 생산 공정의 병목 현상이라는
명확한 한계를 드러내고 있습니다.
이러한 상황에서 최근 중국의 거대 증권사인 국태군안(Guotai Junan)과
해통증권(Haitong)의 리포트, 그리고 유명 팁스터 주칸로스레브(Jukanlosreve)를 통해
구글의 차세대 AI 칩인 'TPU V8'에 관한 파격적인 루머가 전해졌습니다.
구글이 HBM 의존도를 획기적으로 낮추고,
일반 DRAM과 광학 기술을 결합한 새로운 아키텍처를 검토 중이라는 내용입니다.
단순한 비용 절감을 넘어 AI 인프라의 경제학을 다시 쓰려는 구글의 전략적 시나리오를
기술적 관점에서 분석해 봅니다.


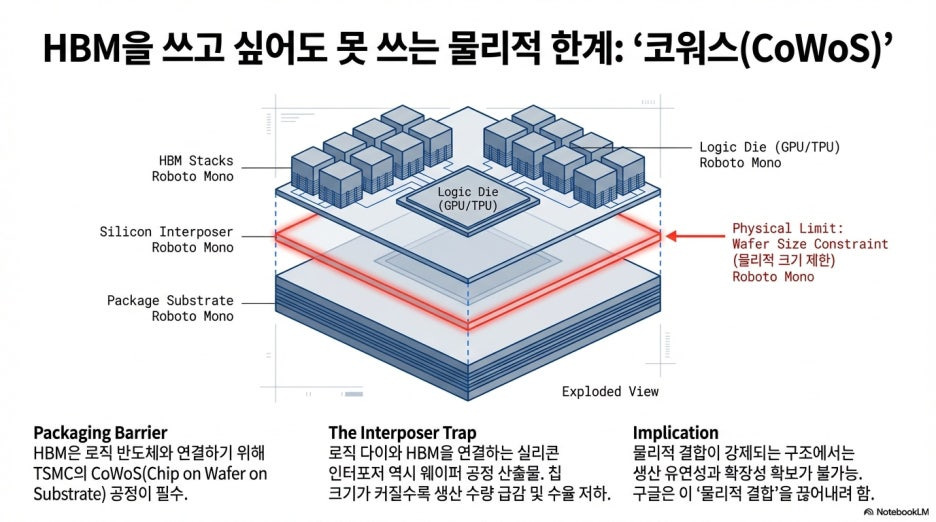
2. [Takeaway 1] HBM을 쓰고 싶어도 못 쓰는 물리적 한계, '코워스(CoWoS)'의 병목
HBM이 직면한 가장 큰 장벽은 역설적이게도 이를 로직 반도체와 연결하는 패키징 기술에 있습니다.
현재 HBM 기반 가속기는 TSMC의 코워스(CoWoS, Chip on Wafer on Substrate) 공정을
필수적으로 거쳐야 합니다.
로직 다이(TPU/GPU)와 HBM을
실리콘 인터포저라는 평평한 판위에 미세하게 연결해 붙여야 하는데,
이 인터포저 역시 웨이퍼 공정으로 생산됩니다.
칩의 크기가 커질수록 웨이퍼 한 장당 생산 가능한 수량이 급감하며,
이는 곧 전체 공급망의 병목으로 이어집니다.
구글의 새로운 구상은
로직 칩과 메모리를 물리적으로 결합해야만 하는 코워스 구조에서 탈피하여,
생산 유연성과 확장성을 확보하려는 전략적 포석으로 풀이됩니다.

3. [Takeaway 2] HBM 대신 거대한 '메모리 캐비닛'과 DRAM 풀의 등장
루머에 따르면 구글은 로직 칩 옆에 HBM을 배치하는 대신,
별도의 독립적인 **'DRAM 메모리 캐비닛'**을 구축하는 설계를 검토하고 있습니다.
이는 16개에서 32개의 메모리 전용 트레이(Tray)로 구성되며,
TPU 한 개당 접근 가능한 메모리 용량을 512GB에서 최대 768GB까지 확장하는
거대한 메모리 풀(Pool) 개념입니다.
"2027년 출시를 목표로 새로운 솔루션을 개발 중인데
요게 HBM을 제거하고 16개에서 32개의 트레이로 구성되어 있는...
독립적인 디램 메모리 캐비닛을 구축한다"
이 방식이 도입되면 고가의 HBM 대신
LPDDR 혹은 RDIMM과 같은 표준 서버용 DRAM 수요가 급증하게 됩니다.
구글은 비용 효율적인 일반 DRAM을 대규모로 병렬 배치하여,
메모리 용량의 한계를 돌파하려는 것으로 보입니다.


4. [Takeaway 3] '3계층 설계'의 마법: 광스위칭(OCS)과 CXL 프로토콜
외부 메모리 캐비닛의 치명적인 약점인 지연 시간(Latency)을 해결하기 위해
구글은 세 가지 계층으로 구성된 시스템 아키텍처를 제안합니다.
전송 계층(Transport Layer)
기존의 구리선 기반 이더넷(Ethernet) 네트워킹은 약 200ns 이상의 지연 시간이 발생합니다.
구글은 이를 광 스위칭(OCS, Optical Circuit Switching) 기술로 대체하여
지연 시간을 100ns 이하로 단축하려 합니다.
저장 계층(Storage/DRAM Layer)
대규모 DRAM 트레이를 배치하여 메모리 용량을 확보하는 층입니다.
제어 계층(Control Layer)
엔비디아의 블루필드(BlueField) DPU처럼, 메모리 관리를 전담하는 전용 CPU/DPU를 두어
효율적인 데이터 핸들링을 수행합니다.
여기에 CXL(Compute Express Link) 프로토콜을 커스터마이징하여 적용함으로써,
물리적으로 떨어진 여러 개의 DRAM 트레이가 하나의 거대한 메모리처럼 동작하는
**'캐시 일관성(Cache Coherency)'**을 확보한다는 계산입니다.


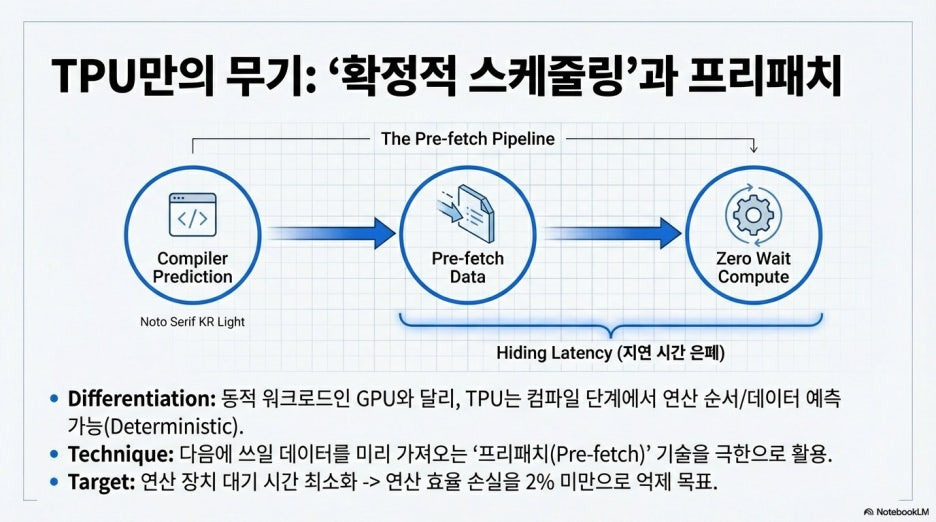
5. [Takeaway 4] TPU만이 가능한 '확정적 스케줄링'과 프리패치(Pre-fetch)
이러한 설계가 범용 GPU가 아닌 구글 TPU이기에 가능한 이유는
TPU 특유의 '디터미니스틱(Deterministic) 스케줄링' 능력에 있습니다.
동적으로 워크로드를 처리하는 엔비디아 GPU와 달리,
구글 TPU는 소프트웨어 컴파일 단계에서 연산 순서와 필요한 데이터를 미리 예측하고 스케줄링할 수 있습니다.
다음에 쓰일 데이터를 미리 외부 메모리에서 가져오는
'프리패치(Pre-fetch)' 기술을 극한으로 끌어올리면,
외부 DRAM을 사용하더라도 연산 장치가 대기하는 시간을 최소화할 수 있습니다.
보고서에 따르면 구글은 이 아키텍처를 통해
연산 효율 손실을 2% 미만으로 억제하는 것을 목표로 하고 있습니다.
이는 하드웨어 설계와 전용 컴파일러를 동시에 통제하는
구글만이 누릴 수 있는 수직 계열화의 강점입니다.

6. [Takeaway 5] '추론(Inference)' 최적화와 KV 캐시 계층화 전략
구글의 아키텍처 혁신은
특히 대규모 서비스 단계인 **'추론(Inference)'**에서 강력한 경제성을 발휘합니다.
학습(Training) 과정에서는
빈번한 데이터 업데이트 때문에 HBM의 대역폭이 필수적이지만,
추론에서는 가중치 데이터를 읽어오는 비중이 훨씬 높기 때문입니다.
구글은 데이터를 성격에 따라 **'핫 KV 캐시(Hot KV Cache)'**와
**'콜드 KV 캐시(Cold KV Cache)'**로 분리할 것으로 보입니다.
즉각적인 응답이 필요한 핫 데이터는 소량의 HBM에 유지하고,
참조 빈도가 낮은 콜드 데이터는 외부 DRAM 풀로 오프로딩(Off-loading)하는 물리적 이원화 전략입니다.
이를 통해 구글 검색이나 유튜브와 같은 매머드급 서비스의 운영 비용을
혁신적으로 절감할 수 있습니다.

7. 결론: 메모리 계층화가 재정의하는 AI 인프라의 미래
구글의 이번 시도는 단순히 HBM을 대체하는 것이 아니라,
HBM과 DRAM, 그리고 광학 기술이 각자의 위치에서 최적의 역할을 수행하는
**'메모리 계층화(Memory Tiering)'**의 표준을 제시하는 과정입니다.
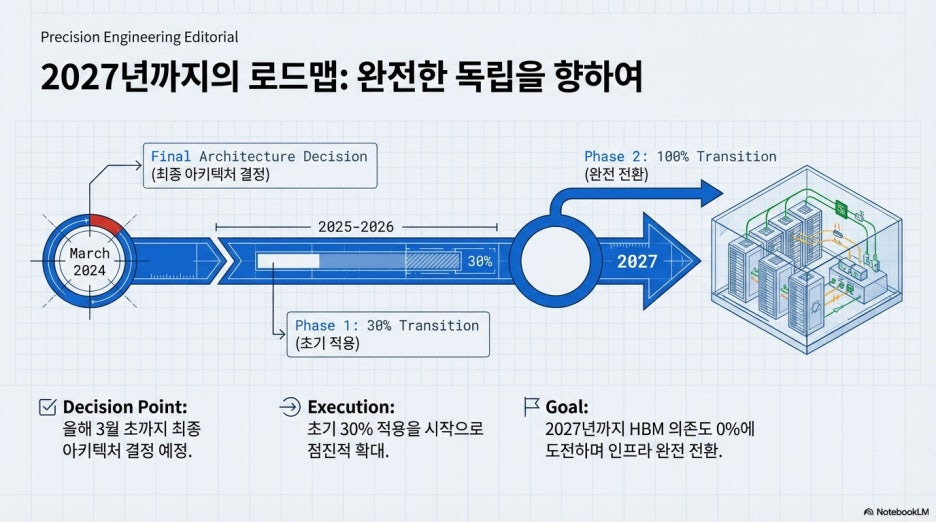
업계에 따르면 구글은 올해 3월 초까지 최종 아키텍처를 결정할 예정이며,
초기 30% 적용을 시작으로 2027년까지 100% 전환한다는 구체적인 로드맵을 그리고 있습니다.


물론 외부 DRAM 풀이
HBM의 물리적 대역폭을 완벽히 대체하기에는 한계가 있다는 신중론도 존재합니다.
그러나 모두가 HBM 확보에 사활을 걸 때,
'빛(OCS)과 DRAM'으로 눈을 돌린 구글의 도박은
엔비디아의 독주 체제를 흔들고 AI 경제학의 새로운 이정표가 될 수 있을까요?
2027년, 구글이 완성할 'HBM으로부터의 독립'이
어떤 결과로 이어질지 전 세계 반도체 업계가 주목하고 있습니다.
관련 동영상
유의해야 할 점 (주의 사항)
소스는 이러한 변화가 아직 루머 단계이며, 구글 TPU와 같이 미리 스케줄링이 가능한
특수한 구조에서만 가능한 시나리오일 수 있다고 경고합니다.
따라서 업계 전반으로 이 기술이 확산될지,
혹은 구글만의 독자적인 노선이 될지에 따라 관련 기업들의 주가 향방이 달라질 수 있습니다.